同濟大學王昊奮 知識圖譜在多模態大數據時代的創新與實踐——世界人工智能大會達觀數據論壇觀點摘要
在近日舉行的世界人工智能大會達觀數據論壇上,同濟大學特聘研究員、博士生導師王昊奮博士圍繞“知識圖譜在多模態大數據時代的創新和實踐”這一主題,分享了前沿的學術洞察與行業實踐經驗。該論壇作為大會的重要組成部分,由達觀數據聯合CSDN等知名技術社區舉辦,聚焦人工智能基礎軟件的開發與應用,吸引了眾多學術界與產業界的專家參與。
王昊奮博士首先指出,隨著大數據技術的飛速發展,數據形態已從傳統的結構化文本,演變為涵蓋文本、圖像、音頻、視頻等多種模態的復雜綜合體。多模態大數據在帶來豐富信息價值的也因其異構性、關聯復雜和語義鴻溝等問題,對信息的深度理解與智能處理提出了巨大挑戰。在這一背景下,知識圖譜作為結構化語義知識庫,成為連接多模態數據、實現認知智能的關鍵基礎設施。
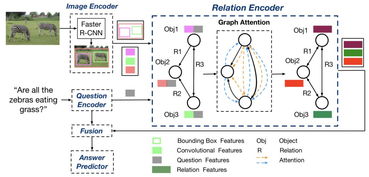
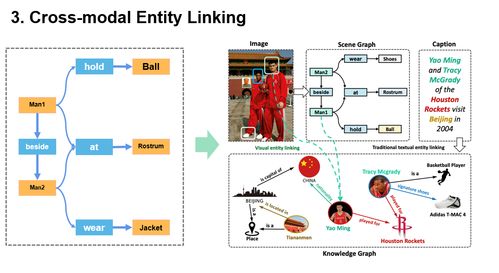
在創新層面,王昊奮重點介紹了其團隊在多模態知識圖譜構建與推理方面的最新探索。傳統知識圖譜主要基于文本構建,而多模態知識圖譜的核心創新在于能夠融合并關聯不同模態數據中的實體與概念。例如,通過計算機視覺技術識別圖像中的物體,通過自然語言處理技術理解描述文本,并將這些信息與知識圖譜中的實體節點進行精準對齊和關聯,從而構建起一個“可看、可聽、可讀”的立體化知識網絡。這種融合不僅豐富了知識的表達維度,也為更高級的語義理解與跨模態檢索、問答等應用奠定了基礎。
在實踐應用方面,王昊奮結合達觀數據等企業在人工智能基礎軟件開發中的實際案例,闡述了多模態知識圖譜如何賦能產業。在智能金融領域,知識圖譜可以整合公司年報、新聞輿情、股價圖表等多源異構數據,構建產業鏈與風險關聯網絡,輔助進行投研分析與風險管控。在智慧醫療領域,通過關聯醫學文獻、臨床影像、病理報告和基因數據,可以構建疾病知識圖譜,輔助醫生進行診斷決策和科研發現。在智能內容審核與推薦領域,多模態知識圖譜能夠深入理解圖文、視頻內容的深層語義與上下文關聯,實現更精準、更安全的審核與個性化推薦。
王昊奮強調,多模態知識圖譜的落地離不開堅實的人工智能基礎軟件棧支撐。這包括高效的多模態數據預處理與特征提取工具、可擴展的知識存儲與計算引擎、以及面向領域的可視化與交互開發平臺。達觀數據等企業在此領域持續投入,致力于開發低代碼、高性能的知識圖譜平臺,降低技術應用門檻,推動知識圖譜技術在更多行業場景中規模化落地。
王昊奮展望了未來趨勢。他認為,多模態知識圖譜將與大規模預訓練模型(如多模態大模型)深度融合。知識圖譜能為大模型提供結構化的先驗知識,提升其推理的可解釋性與準確性;而大模型強大的語義表示與生成能力,又能反過來助力知識圖譜的自動化構建與動態演化。兩者協同,將共同驅動下一代人工智能系統向更深層次的認知與決策智能邁進。
本次分享在CSDN等技術博客社區也引發了廣泛討論,為從事人工智能基礎軟件研發的工程師和研究人員提供了寶貴的思路與方向。知識圖譜作為AI的“知識大腦”,正在多模態大數據時代扮演愈加核心的角色,其創新與實踐將持續推動人工智能技術賦能千行百業。
如若轉載,請注明出處:http://www.gzyhjm.cn/product/6.html
更新時間:2026-06-01 13:51:57